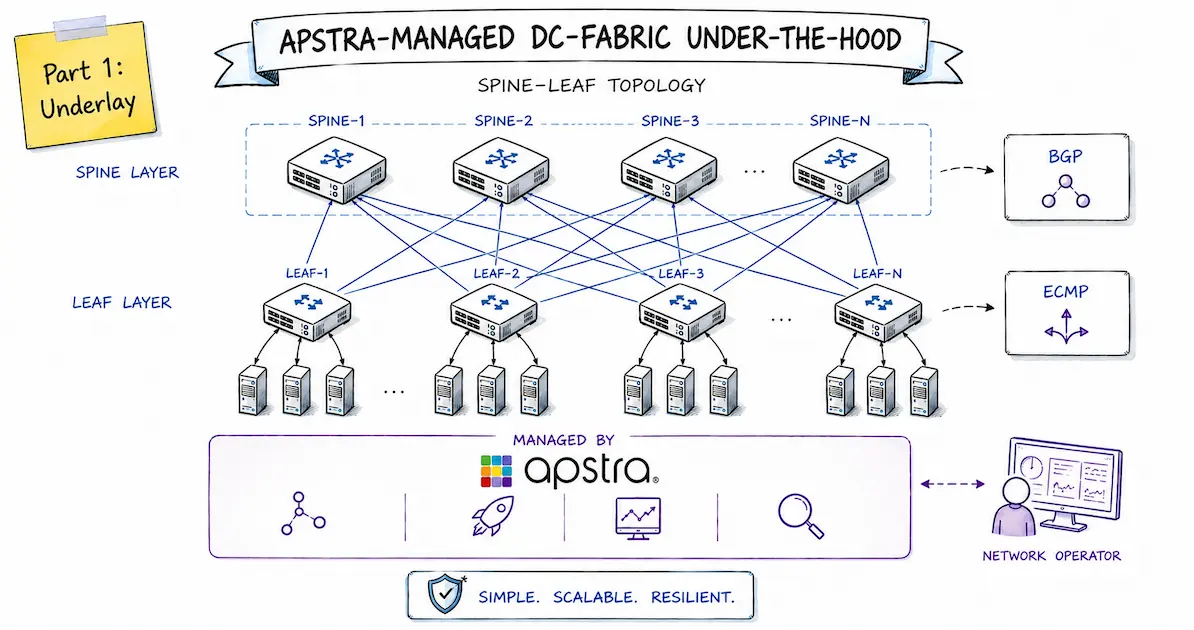
Apstra DC-Fabric als Lösung
In meinem letzten Blog Posts habe ich bereits HPE Juniper Apstra als multi-vendor Managementlösung für Datacenter-Netzwerke erwähnt und demonstriert wie man das System gemeinsam mit den zugehörigen Fabric-Switches in einer Containerlab-Topologie betreiben kann.
In diesem Post, der den ersten Teil einer Serie von Beiträgen darstellt, soll es darum gehen Apstra als Lösung und die darüber verwalteten DC-Fabrics aus Sicht eines Network Engineers besser zu verstehen. Auch wenn Apstra als sog. “Intent-based Networking” Lösung einen hohen Abstrakionsgrad im Bereitstellen und Betreiben von DC-Netzwerken ermöglicht und keine tiefe Netzwerk-Expertise voraussetzt, ist es aus meiner Sicht unerlässlich möglichst genau zu verstehen, welche Designs und letztlich auch Konfigurationen auf Device-Ebene der Gesamtlösung zu Grunde liegen.
Demo Topologie
Im Rahmen dieser Serie werde ich nur am Rand auf die Modellierung in Apstra eingehen, denn hierzu gibt es m.E. ausreichend Dokumentation und Beispiele. Es soll viel mehr darum gehen exemplarisch das zugrundeliegende Design, Konfigurationen und Besonderheiten kennenzulernen, um daraus die wesentlichen Mechaniken der Lösung, sowie Stärken und Schwächen besser einschätzen zu können.
Die folgende Abbildung stellt die von mir verwendete Demo-Topologie in Apstra dar:
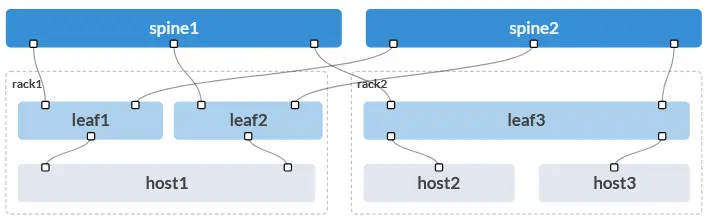
Ich verwende eine simple und überschaubare 3-stage Clos Fabric mit den folgenden Merkmalen:
- Spine-Layer bestehend aus 2 Spine-Switches
- Leaf-Layer bestehend aus 2 Racks
- Rack 1 mit einem Leaf-Pair bestehend aus Leaf1 und Leaf2, an dem der dual-homed Host1 angebunden ist
- Rack 2 mit dem standalone Leaf3, an dem zwei single-homed Hosts angebunden sind
Teil 1 - Underlay Netzwerk
Dieser Blog-Post widmet sich dabei zu Beginn dem Underlay-Netzwerk.
IP-Adressierung
Auf Basis der Demo-Topologie setzt Apstra das folgende Underlay-Design inkl. IP-Adressierung auf den Geräten um:
Sämtliche internen physischen Fabric-Links werden dabei als Layer-3 Point-to-Point Links konfiguriert, wie hier am Beispiel der Spine1 Config zu sehen:
interfaces {
ge-0/0/0 {
description facing_leaf1:ge-0/0/0;
mtu 9192;
unit 0 {
family inet {
mtu 9170;
address 172.16.0.0/31;
}
}
}
ge-0/0/1 {
description facing_leaf2:ge-0/0/0;
mtu 9192;
unit 0 {
family inet {
mtu 9170;
address 172.16.0.2/31;
}
}
}
ge-0/0/2 {
description facing_leaf3:ge-0/0/0;
mtu 9192;
unit 0 {
family inet {
mtu 9170;
address 172.16.0.4/31;
}
}
}
[...]
lo0 {
unit 0 {
family inet {
address 203.0.113.0/32;
}
}
}
}
Auf den phys. Interfaces wird dabei standardmäßig eine MTU von 9192 Byte und auf den logischen L3-Interfaces (unit 0) von 9170 Byte eingestellt, um später auch Jumbo-Frames in den Overlay-Services zu ermöglichen.
Jeder Fabric-Switch erhält zudem ein Loopback-Interface (lo0), dessen IP-Adresse sowohl als Router-ID für BGP dient. Bei den Leaf-switches fungiert dieses Interface ebenfalls als VTEP.
Underlay-Routing
Die Hauptaufgabe des Underlay-Netzwerkes ist die Ende-zu-Ende Errerichbarkeit der Loopback-Interfaces aller Leaf-Switches sicherzustellen, da diese später als VTEPs für die VXLAN-basierten Overlay-Services verwendet werden.
Apstra setzt im Underaly als dynamisches Routingprotokoll auf External BGP (eBGP). Und zwar wird auf jedem P2P-Link eine eBGP-Nachbarschaft mit der Adress-Family IPv4 zwischen den Spine- und Leaf-Switches etabliert:
Sämtliche Underlay-relevanten BGP-Konfigurationen sind dabei unter der Gruppe l3clos-l (bei allen Leaf-Switches), respektive l3clos-s (bei allen Spine-Switches) zu finden.
Am Beispiel des Leaf1 sieht man, dass auf Gruppenebene sowohl BGP multipath als auch multiple-as gesetzt sind. Dies ist erforderlich um Control-PLane-seitig ein Loadbalancing über sämtliche verfügbaren Links auf Basis von “Equal-Cost-Multipath” (ECMP) zu ermöglichen. Wären diese Optionen nicht gesetzt, würde gem. Standard eBGP-Logik jeweils nur einer der verfügbaren Pfade genutzt werden.
protocols {
[...]
bgp {
group l3clos-l {
type external;
multipath {
multiple-as;
}
bfd-liveness-detection {
minimum-interval 1000;
multiplier 3;
}
neighbor 172.16.0.0 {
description facing_spine1;
local-address 172.16.0.1;
family inet {
unicast;
}
export ( LEAF_TO_SPINE_FABRIC_OUT && BGP-AOS-Policy );
peer-as 64512;
}
neighbor 172.16.0.6 {
description facing_spine2;
local-address 172.16.0.7;
family inet {
unicast;
}
export ( LEAF_TO_SPINE_FABRIC_OUT && BGP-AOS-Policy );
peer-as 64513;
}
vpn-apply-export;
}
[...]
log-updown;
graceful-restart {
dont-help-shared-fate-bfd-down;
}
multipath;
}
Für alle eBGP-Nachbarn im Underlay wird jeweils nur die IPv4-Adressfamilie mittels family inet unicast aktiviert, sodass alle Underlay-Routen in der Default-Routingtabelle inet.0 zu finden sind. Zusätzlich wird BFD mit einer Erkennungszeit von 3x1000ms aktiviert, um indirekte Linkfehler zu adressieren. Grundsätzlich wird aber bei direkten Linkfehlern (“Interface Down”) jeweils direkt die entsprechende eBGP-Nachbarschaft terminiert.
Damit das ECMP-Prinzip tatsächlich auch auf Ebene der Forwarding-Plane umgesetzt wird, ist unter den routing-options noch die Forwarding-Table Export Policy PFE-LB aktiviert. Darüber hinaus wird ecmp-fast-reroute genutzt, um die Umschaltzeit bei Ausfällen von Spine-Leaf-Links zu optimieren.
routing-options {
router-id 203.0.113.2;
autonomous-system 64514;
graceful-restart;
forwarding-table {
export PFE-LB;
ecmp-fast-reroute;
chained-composite-next-hop {
ingress {
evpn;
}
}
}
}
[...]
policy-options {
[...]
policy-statement PFE-LB {
then {
load-balance per-packet;
}
}
[...]
}
Die zusätzliche Config-Option chained-composite-next-hop ingress evpn auf allen Leaf-Switches bezieht sich eher auf Optimierungen für die Overlay-Services, nutzt dabei aber die Underlay-VTEP Next-Hop Einträge, indem sie eine hierarchische Next-Hop-Auflösung für EVPN-Routen aktiviert.
Des Weiteren wird global auch graceful-restart aktiviert mit dem Zusatz dont-help-shared-fate-bfd-down unter der BGP-Config. Dadurch wird einerseits die Bewahrung der Routen und ein sanftes Wiederherstellen der BGP-Sessions bei Control-Plane-Neustarts ermöglicht, während andererseits bei tatsächlich ausgefallenem Peer oder Link, die durch duch BFD erkannt werden, sofort sämtliche betroffenen Routen zurückgezogen werden.
Policy
Leaf-Switches
Wie im o.g. Config-Auszug zu sehen sind auch die folgenden beiden Export-Policies für die Underlay-eBGP Sessions auf sämtlichen Leaf-Switches aktiviert:
LEAF_TO_SPINE_FABRIC_OUTBGP-AOS-Policy
Durch die logische UND-Verknüfung der Policies in der BGP-Config export ( LEAF_TO_SPINE_FABRIC_OUT && BGP-AOS-Policy ) werden nur Routen propagiert, die mit beiden Policies übereinstimmen.
Im Detail sehen die relevanten Policies wie folgt aus:
policy-options {
policy-statement AllPodNetworks {
term AllPodNetworks-10 {
from {
family inet;
protocol direct;
}
then {
community add DEFAULT_DIRECT_V4;
accept;
}
}
term AllPodNetworks-100 {
then reject;
}
}
policy-statement BGP-AOS-Policy {
term BGP-AOS-Policy-10 {
from policy AllPodNetworks;
then accept;
}
term BGP-AOS-Policy-100 {
then reject;
}
}
}
policy-statement LEAF_TO_SPINE_FABRIC_OUT {
term LEAF_TO_SPINE_FABRIC_OUT-10 {
from {
protocol bgp;
community FROM_SPINE_FABRIC_TIER;
}
then reject;
}
term LEAF_TO_SPINE_FABRIC_OUT-20 {
then accept;
}
}
}
community DEFAULT_DIRECT_V4 members [ 3:20007 21001:26000 ];
community FROM_SPINE_FABRIC_TIER members 0:15;
Diese Export-Policies stellen sicher, dass ein Leaf-Switch nur seine eigenen direkt verbundenen IPv4 Underlay-Routen (Loopbacks / P2P-Links) an die Spines propagiert, während gleichzeitig verhindert wird, dass die gelernten Routen von einem Spine an den anderen Spine weiterpropagiert werden (-> Routing-Loop). Diese zusätzliche Policy-seitige Absicherung ist in diesem Fall erforderlich, da beide Spines unterschiedliche ASNs verwenden und ein Loop somit nicht anhand des AS-Pfads erkannt und aufgelöst werden kann.
Spine-Switches
Bei den Spine-Switches sehen die Policies leicht unterschiedlich aus:
SPINE_TO_LEAF_FABRIC_OUTBGP-AOS-Policy
policy-options {
policy-statement AllPodNetworks {
term AllPodNetworks-10 {
from {
family inet;
protocol direct;
}
then {
community add DEFAULT_DIRECT_V4;
accept;
}
}
term AllPodNetworks-100 {
then reject;
}
}
policy-statement BGP-AOS-Policy {
term BGP-AOS-Policy-10 {
from policy AllPodNetworks;
then accept;
}
term BGP-AOS-Policy-20 {
from protocol bgp;
then accept;
}
term BGP-AOS-Policy-100 {
then reject;
}
}
policy-statement SPINE_TO_LEAF_FABRIC_OUT {
term SPINE_TO_LEAF_FABRIC_OUT-10 {
then {
community add FROM_SPINE_FABRIC_TIER;
accept;
}
}
}
community DEFAULT_DIRECT_V4 members [ 1:20007 21001:26000 ];
community FROM_SPINE_FABRIC_TIER members 0:15;
}
Die Spine-Policies sorgen dafür, dass der Spine sowohl seine eigenen direkt verbundenen Routen als auch alle von Leafs per BGP gelernten Routen an andere Leafs weiterverteilt, diese dabei mit einer Community kennzeichnet, sodass Leafs diese Routen nicht erneut zu den Spines zurückpropagieren. Somit wird auch das Valley-Free Routing sichergestellt, und verhindert, dass Leaf-Switches als Transit-Device benutzt werden.
Verifikation
Abschließend schauen wir uns noch an, wie das Ende-zu-Ende Underlay-Routing und das ECMP-Loadbalancing überprüft werden können. Zur Verifikation nutze ich exemplarisch wieder den Leaf1 und schaue mir dabei die folgenden Outputs an:
- show bgp summary
- show route table inet.0
- show route forwarding-table
show bgp summary
Threading mode: BGP I/O
Default eBGP mode: advertise - accept, receive - accept
Groups: 2 Peers: 4 Down peers: 0
Table Tot Paths Act Paths Suppressed History Damp State Pending
inet.0
16 10 0 0 0 0
[...]
Peer AS InPkt OutPkt OutQ Flaps Last Up/Dwn State|#Active/Received/Accepted/Damped...
172.16.0.0 64512 105 102 0 0 45:10 Establ
inet.0: 5/8/8/0
172.16.0.6 64513 15 11 0 0 4:30 Establ
inet.0: 5/8/8/0
[...]
Wie im Outut zu sehen, ind die beiden eBGP-Sessions zu den Spine-Switches mit unterschiedlichen ASNs und der Adressfamile IPv4 Unicast aktiv (Established) und es werden aktive Pakete und Routen ausgetauscht.
show route table inet.0
inet.0: 13 destinations, 21 routes (13 active, 0 holddown, 0 hidden)
Restart Complete
Limit/Threshold: 1048576/1048576 destinations
+ = Active Route, - = Last Active, * = Both
[...]
172.16.0.1/32 *[Local/0] 00:50:03
Local via ge-0/0/0.0
[...]
172.16.0.7/32 *[Local/0] 00:50:03
Local via ge-0/0/1.0
[...]
203.0.113.0/32 *[BGP/170] 00:47:49, localpref 100
AS path: 64512 I, validation-state: unverified
> to 172.16.0.0 via ge-0/0/0.0
203.0.113.1/32 *[BGP/170] 00:07:10, localpref 100
AS path: 64513 I, validation-state: unverified
> to 172.16.0.6 via ge-0/0/1.0
203.0.113.2/32 *[Direct/0] 00:50:20
> via lo0.0
203.0.113.3/32 *[BGP/170] 00:07:03, localpref 100, from 172.16.0.0
AS path: 64512 64515 I, validation-state: unverified
to 172.16.0.0 via ge-0/0/0.0
> to 172.16.0.6 via ge-0/0/1.0
[BGP/170] 00:07:03, localpref 100
AS path: 64513 64515 I, validation-state: unverified
> to 172.16.0.6 via ge-0/0/1.0
203.0.113.4/32 *[BGP/170] 00:07:02, localpref 100, from 172.16.0.0
AS path: 64512 64516 I, validation-state: unverified
to 172.16.0.0 via ge-0/0/0.0
> to 172.16.0.6 via ge-0/0/1.0
[BGP/170] 00:07:02, localpref 100
AS path: 64513 64516 I, validation-state: unverified
> to 172.16.0.6 via ge-0/0/1.0
In der Default-Routingtabelle inet.0 sind sämtliche Underlay-Routinginformationen zusammengefasst. Man sieht gut, dass die Loopback-IPs der anderen Leaf-Switches (203.0.113.3/32 und 203.0.113.4/32) empfangen werden und über zwei AS-Pfade (= zwei Spines) verfügbar sind.
show route forwarding-table
Routing table: default.inet
Internet:
Destination Type RtRef Next hop Type Index NhRef Netif
default perm 0 rjct 36 1
0.0.0.0/32 perm 0 dscd 34 1
[...]
203.0.113.1/32 user 1 172.16.0.6 ucst 578 8 ge-0/0/1.0
203.0.113.2/32 intf 0 203.0.113.2 locl 512 1
203.0.113.3/32 user 0 ulst 1048574 3
172.16.0.0 ucst 577 8 ge-0/0/0.0
172.16.0.6 ucst 578 8 ge-0/0/1.0
203.0.113.4/32 user 0 ulst 1048574 3
172.16.0.0 ucst 577 8 ge-0/0/0.0
172.16.0.6 ucst 578 8 ge-0/0/1.0
[...]
255.255.255.255/32 perm 0 bcst 32 1
Durch diesen Output können wir zusätzlich noch die Forwarding-Table und die Umsetzung des ECMP-Loadbalincing überprüfen. Auch hier lässt sich ablesen, dass die beiden Loopback-IPs der Remote-Leafs jeweils über zwei aktive Next-Hops im Underlay erreichbar sind.
Fazit
Ich hoffe, dass dieser erste Teil der Serie einen guten Überblick und ein besseres Verständnis von Design und Implementierung des Underlay-Netzwerks in Apstra-managed DC-Fabrics mit Juniper Fabric-Switches ermöglicht. Ich finde man sieht dabei bereits sehr deutlich, wie sich bestimmte Design-Entscheidungen (z.B. unterschiedliche Spine ASNs) dann auch auf die Konfiguration und deren Komplexität auswirken (z.B. Sicherstellung von Loop- und Valley-Free Routing durch Custom BGP-Policies).
Im nächsten Teil der Serie werde ich dann näher auf die Umsetzung des EVPN-Overlays eingehen.