Die Idee
Wer mit HPE Juniper Apstra als multi-vendor Managementlösung für Datacenter-Netzwerke arbeitet, weiß dass eine entsprechende Testumgebung unerlässlich ist. Die Wenigsten möchten wahrscheinlich neue Features, Änderungen am System oder Automatisierungs-Workflows im Produktiv-Netz verproben.
Im besten Fall kann man eine zusätzliche Apstra Server VM für diese Zwecke auf der hauseigenen Virtualisierungs-Infrastruktur bereitstellen. Solange diese aber ohne tatsächliche “Managed Devices” arbeitet, sind die Erkenntnisse daraus eher theoretischer Natur.
Natürlich könnte man darüber hinaus auch mit den etablierten Netzwerk Emulationsplattformen, wie EVE-ng, GNS3 oder Cisco CML arbeiten, um ein entprechendes Lab auf Basis virtualisierter Komponenten aufzubauen. Da dieses Unterfangen aber auch wieder an entsprechende Infrastrukturvoraussetzungen, wie Bare-Metal Server bzw. entsprechend potenter Hardware und deren Verfügbarkeit/Erreichbarkeit geknüpft ist, möchte ich in diesem Blog Post einen weiteren - eher leichtegwichtigen Ansatz vorstellen, mit dem man ein komplettes Apstra-managed Datacenter-Netzwerk bspw. auch auf dem lokalen Laptop laufen lassen kann.
Apstra und Containerlab
Das Tool der Wahl für diesen Use-Case ist m.E. mal wieder Containerlab. Nachdem ich in einem der letzten Blog Posts das Setup von Containerlab unter Windows ausführlich beschrieben habe, soll die Containerlab WSL Distro auch hier als Basis dienen.
Während es im besagten Blog Post aber vergleichsweise einfach war einzelne Container-basierte Nodes in Containerlab zu integrieren, so bringt die Integration von Apstra gewisse Herausforderungen mit sich. Schaut man sich die aktuell unterstützten “Node Kinds” von Containerlab an, fällt auf, dass Juniper Apstra nicht direkt aufgeführt ist.
Neben den voll unterstützen “Node Kinds” für individuelle Hersteller-Appliances, wie z.B auch dem VM-basierten Juniper vJunos-Switch findet man auf der Liste auch noch einen Eintrag mit dem Namen “Generic VM”. Dieser Node-Typ ist dafür vorgesehen “beliebige VMs zu starten, die mithilfe von vrnetlab in einen Container gepackt wurden” und scheint somit für den gewünschten Use-Case das Mittel der Wahl zu sein.
Containerlab vrnetlab-Fork
Für das weitere Verständis muss zuerst geklärt werden was vrnetlab eigentlich ist und welche Rolle es bei dem ganzen Unterfangen spielt. Das erwähnte vrnetlab-Projekt, bzw. in diesem konkreten Fall der vrnetlab-Fork von srl-labs sorgt letztlich dafür, dass VMs in Containerlab-kompatible Docker Container gepackt werden. Das Projekt, besteht dafür aus einer Sammlung von Build-Instruktionen und den notwendigen -Files (Dockerfile, Makefile, Launch-Skript) für die verschiedensten Appliances unterschiedlicher Hersteller.
Wenn man über ein entprechend unterstützes VM-Image (z.B. Juniper vJunos-Switch oder Cisco Cat9kv) verfügt, dann cloned man das Repository, schiebt das Image einfach in den dafür vorgesehenen Ordner und führt den make Befehl aus. Im Anschluss wird der gewünschte Docker-Container gebaut und in das lokale Image-Repository importiert.
Bei näherer Auseinandersetzung mit dem vrnetlab-Repo fällt allerdings auf, dass es keinen vordefinierten Ordner bspw. für den Node-Typ Generic VM oder etwas vergleichbares gibt. Es existiert zwar ein Ordner für Ubuntu, jedoch kann der nur für Standard Ubuntu Cloud-Images verwendet werden. Packt man das Apstra VM-Image in diesen Ordner dann schlägt der Build-Prozess fehl.
Nach etwas Recherche im Containerlab Community Discord stellte sich dann auch heraus, dass ich bisher wohl der erste und einzige war, der auf die Idee kam Apstra als Node innerhalb von Containerlab zu betreiben. Andere, die Apstra in Verbindung mit Containerlab Topologien verwenden, bevorzugen es Apstra außerhalb von Containerlab bspw. als native KVM-VM auf dem Containerlab-Host zu starten (wie z.B. in diesem Juniper Techpost Artikel). An dieser Stelle habe ich zwei Dinge realisiert - erstens, dass ich die notwendigen Build-Instruktionen und -Files für Apstra wohl selbst erstellen müsste - und zweitens, dass meine Idee Apstra in die Containerlab Topologie zu packen vielleicht doch nicht so eine gute Idee wäre 🤔.
Custom Apstra Build-Ordner
Ich war trotzdem nach wie vor davon überzeugt, dass es für gewisse Anwendungsfälle von Vorteil wäre Apstra direkt in der Containerlab Topologie zu verwalten. Von daher habe ich mir angeschaut, wie vrnetlab strukturiert ist und wie man individuelle VM-Typen dort hinterlegen könnte.
Funktionsweise von vrnetlab
Die Grundstruktur von vrnetlab beinhaltet einige Basisdateien, die für alle VM-Typen gleichermaßen herangezogen werden und im Root-Verzeichnis bzw. common Ordner zu finden sind. Darüber hinaus gibt es für jeden individuellen Node-Typ einen spezifischen Build-Ordner, der die individuellen Einstellungen in Form von drei Dateien berücksichigt. Dieser ist typischerweise unter dem entsprechenden Herstellerverzeichnis zu finden.
vrnetlab/
├── makefile.include <- gemeinsame Make-Targets für alle Node-Typen (docker-image, docker-push usw.)
├── makefile-sanity.include <- überprüft DOCKER_REGISTRY und setzt REGISTRY Variable
├── common/
│ ├── vrnetlab.py <- VM- + VR-Basisklassen, QEMU-Lifecycle, Health Reporting
│ └── healthcheck.py <- benötigt für Docker healthcheck
└── <vendor>/
└── <vm-type>/
├── Makefile <- VENDOR/NAME/IMAGE_GLOB/VERSION, einschließlich gemeinsam genutzter Makefiles
└── docker/
├── Dockerfile <- schließt vrnetlab Base-Image ein, kopiert „qcow2“ und „launch.py“, gibt Ports frei
└── launch.py <- Node-spezifische VM- + VR-Klassen, QEMU config, bootstrap_spin() Skript
Die Aufgabe bestand nun also darin die benötigten Files für einen neuen Apstra VM-Typ zu erstellen und unter dem Herstellerverzeichnis juniper abzulegen. Für diesen Zweck habe ich allerdings die Unterstützung von KI in Form von Claude in Anspruch genommen. Ich habe weder die notwendigen Hands-on Erfahrungen im Umgang mit Dockerfiles, Makefiles und launch-Skripten, noch in der spezifischen vrnetlab-Logik.
KI als Helfer
Claude hat die Aufgabe und das Ziel zu Beginn auch direkt mit dem ersten Prompt verstanden und auch die grundlegend benötigten Einstellungen anhand seiner Kenntnis der Apstra Dokumentation abgeleitet. Es hat allerdings im weiteren Verlauf einige zusätzliche Prompts benötigt, um die Instruktionen so anzupassen, das das erstellte Image tatsächlich auch gestartet werden konnte. Weitere Prompts waren dann nötig, damit bspw. alle benötigten Ports exponiert wurden und auch ein persistentes Overlay-Image angelegt wird, welches den Zustand der VM auch nach Herunterfahren der Lab-Topologie erhält. Es gab auch Fälle bei denen sich Claude etwas “verrannt” hatte und unnötig komplexe Ansätze verfolgt hatte, sodass man ihn kurz wieder einfangen musste. Zudem ist mir auch aufgefallen, dass Claude nicht immer auf die aktuellsten Daten bspw. des vrnetlab-Repos auf Github oder auch der Juniper Doku zu Apstra zugreifen kann. Dann hilft es bspw. auch ihm diese konkreten Daten direkt über den Chat zur Verfügung zu stellen.
Alles in allem hat dieser Ansatz aber zun Ziel geführt und ich war in der Lage einen individuellen Build-Ordner für Juniper Apstra zusammenzustellen, der funktionierende Containerlab-Images erstellte. ✅
Auch der Weg dahin war für mich durchaus erkenntnisreich und ich konnte einiges über die vrnetlab-Funktionsweise und den Umgang mit KI für entsprechende Projekte lernen. Nun war es aber an der Zeit das Ganze tatsächlich mit anderen Nodes in Containerlab zusammenzubringen.
Test
Da sich Apstra als multi-vendor Managementlösung für Datacenter-Netzwerke versteht und neben Juniper u.a. auch Arista Switches unterstützt wollte ich als ultimativen Test eine kleine DC-Fabric, bestehend aus vier Arista cEOS-Nodes aufbauen, die vollständig über Apstra konfiguriert und überwacht wird. In diesem Abschnitt werde ich detailliert auf die dafür notwendigen Schritte eingehen.
Erstellen des Apstra-Images
Zu Beginn erstellen wir das notwendige Apstra Docker-Image unter Verwendung des Custom Apstra Build-Ordners. Dazu laden wir die gewünschte Apstra-Version von der Juniper-Website im KVM-/QCOW2-Format (“Apstra VM Image for Linux KVM”) herunter. In meinem Beispiel verwende ich Apstra v6.1.1.
Dazu können wir die Direktlink-URL nutzen, den Juniper im letzten Schritt des Download-Dialogs anbietet:
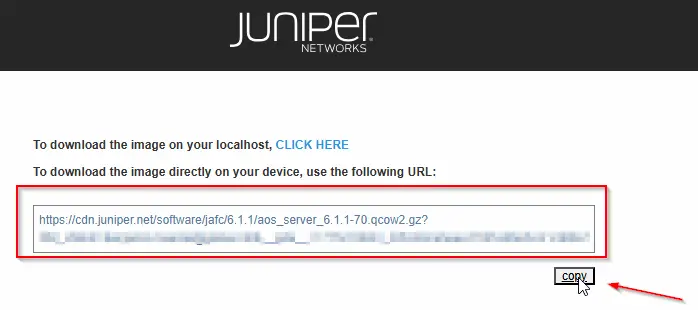
cd vrnetlab/juniper/apstra/
wget -O aos_server_6.1.1-70.qcow2.gz "https://cdn.juniper.net/software/jafc/6.1.1/aos_server_6.1.1-70.qcow2.gz?<USER_SPECIFIC_CREDENTIALS>"
Im Anschluss muss das Achiv, das das KVM-Image entält noch per gunzip entpackt werden, sodass der Apstra Build-Ordner danach wie folgt aussehen müsste:
gunzip aos_server_6.1.1-70.qcow2.gz
[*]─[LAPTOP]─[~/vrnetlab/juniper/apstra]
└──> ll
total 6623392
drwxr-xr-x 3 clab clab 4096 Apr 3 12:18 ./
drwxr-xr-x 9 clab clab 4096 Mar 14 12:18 ../
-rw-r--r-- 1 clab clab 1225 Mar 14 13:57 Makefile
-rw-r--r-- 1 clab clab 10010 Mar 24 08:56 README.md
-rw-r--r-- 1 clab clab 6782320640 Feb 24 17:23 aos_server_6.1.1-70.qcow2
drwxr-xr-x 2 clab clab 4096 Mar 21 12:14 docker/
Nun kann das Docker-Image mit dem make-Befehl erstellt werden und danach mit Hilfe von docker images überprüft werden, ob das der Build-Vorgang erfolgreich war:
[*]─[LAPTOP]─[~/vrnetlab/juniper/apstra]
└──> make
for IMAGE in aos_server_6.1.1-70.qcow2; do \
echo "Making $IMAGE"; \
make IMAGE=$IMAGE docker-build; \
make IMAGE=$IMAGE docker-clean-build; \
done
Making aos_server_6.1.1-70.qcow2
make[1]: Entering directory '/home/clab/labs/vrnetlab/juniper/apstra'
--> Cleaning docker build context
rm -f docker/*.qcow2* docker/*.tgz* docker/*.vmdk* docker/*.iso docker/*.xml docker/*.bin
rm -f docker/healthcheck.py docker/vrnetlab.py
Building docker image using aos_server_6.1.1-70.qcow2 as vrnetlab/juniper_apstra:6.1.1-70
make IMAGE=$IMAGE docker-build-image-copy
make[2]: Entering directory '/home/clab/labs/vrnetlab/juniper/apstra'
cp aos_server_6.1.1-70.qcow2* docker/
make[2]: Leaving directory '/home/clab/labs/vrnetlab/juniper/apstra'
(cd docker; docker build --build-arg http_proxy= --build-arg HTTP_PROXY= --build-arg https_proxy= --build-arg HTTPS_PROXY= --build-arg IMAGE=aos_server_6.1.1-70.qcow2 --build-arg VERSION=6.1.1-70 --label "vrnetlab-version=$(git log -1 --format=format:"Commit: %H from %aD")" -t vrnetlab/juniper_apstra:6.1.1-70 .)
[+] Building 97.3s (8/8) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.2s
=> => transferring dockerfile: 407B 0.0s
=> [internal] load metadata for ghcr.io/srl-labs/vrnetlab-base:0.2.1 0.0s
=> [internal] load .dockerignore 0.1s
=> => transferring context: 2B 0.0s
=> CACHED [1/3] FROM ghcr.io/srl-labs/vrnetlab-base:0.2.1 0.0s
=> [internal] load build context 48.5s
=> => transferring context: 6.78GB 48.5s
=> [2/3] COPY aos_server_6.1.1-70.qcow2 / 37.3s
=> [3/3] COPY *.py / 0.1s
=> exporting to image 10.8s
=> => exporting layers 10.7s
=> => writing image sha256:d2e1e8d18d848d9d37fbc6935950029a6387a1c633737ca05c386c884ceb7c0b 0.0s
=> => naming to docker.io/vrnetlab/juniper_apstra:6.1.1-70 0.0s
make[1]: Leaving directory '/home/clab/labs/vrnetlab/juniper/apstra'
make[1]: Entering directory '/home/clab/labs/vrnetlab/juniper/apstra'
--> Cleaning docker build context
rm -f docker/*.qcow2* docker/*.tgz* docker/*.vmdk* docker/*.iso docker/*.xml docker/*.bin
rm -f docker/healthcheck.py docker/vrnetlab.py
make[1]: Leaving directory '/home/clab/labs/vrnetlab/juniper/apstra'
[*]─[LAPTOP]─[~/vrnetlab/juniper/apstra]
└──> docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
vrnetlab/juniper_apstra 6.1.1-70 d2e1e8d18d84 3 minutes ago 7.27GB
ceos 4.33.7M 20eaa262cad4 5 days ago 2.47GB
[...]
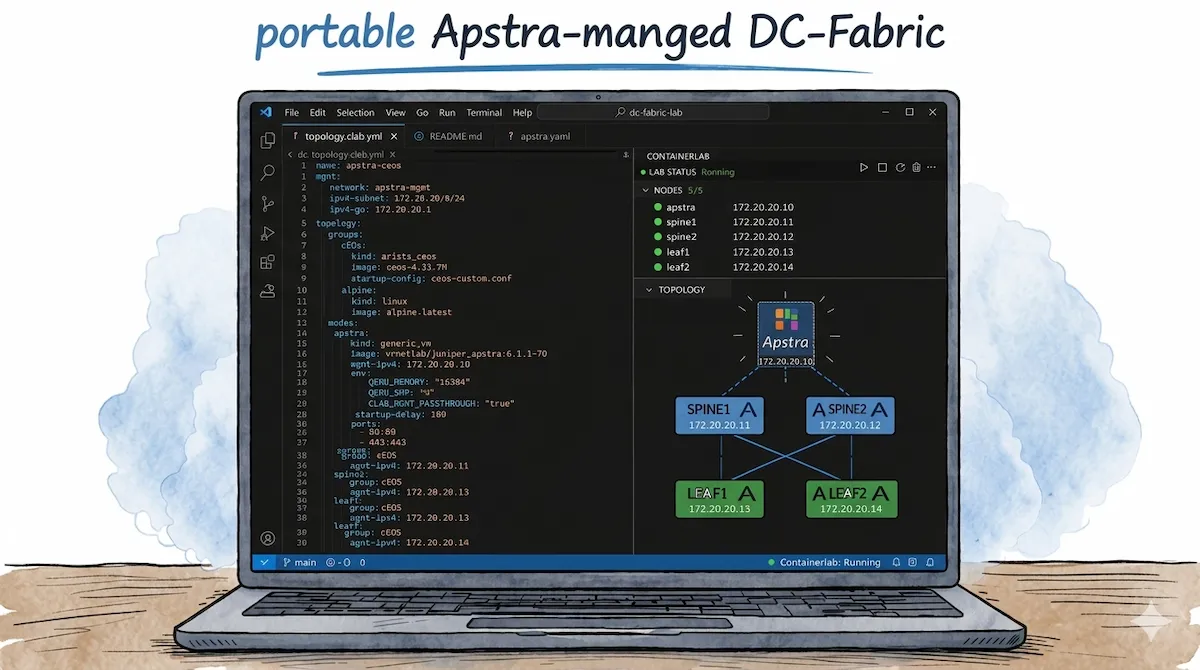
Topologiedefinition
Da das Apstra Container-Image nun hinterlegt ist, können wir uns an die Definition der Containerlab-Topolgie machen. Das Lab besteht neben der Apstra Controller Node aus je zwei Arista cEOS Nodes als Spine-Switches und zwei cEOS Nodes als Leaf-Switches. Zusätzlich nutze ich noch zwei Alpine Linux Nodes als Test-Hosts, die jeweils mit den Leaf-Switches verbunden sind.
Bei der Definition der Apstra-Node sind die folgenden Dinge zu beachten:
| Parameter:Wert | Bedeutung |
|---|---|
kind:generic_vm | ERFORDERLICH: Wir verwenden den generic_vm Node-Typ für beliebige VM-basierte Nodes, die keinen spezifischen Node-Typ definiert haben |
image:vrnetlab/juniper_apstra:6.1.1-70 | ERFORDERLICH: Hier verwenden wir das Docker-Image, welches im vorangegangenen Schritt erstellt wurde. |
mgmt-ipv4:172.20.20.10 | ERFORDERLICH: Definiert eine statische MGMT IPv4-Adresse für die Apstra Node.
Info Diese MGMT-IP muss beim ersten Start manuell mithilfe des First Boot Configuration Tool (aos-config) auf der Apstra CLI gesetzt werden. |
env:QEMU_MEMORY:"16384" | OPTIONAL: Ich verwende für mein Lab 16GB RAM für die Apstra-VM, was der minimalen Herstellerempfehlung entspricht und gleichzeitig auch der Standard-Wert ist, der durch den vrnetlab-Build vorgesehen wird. |
env:QEMU_SMP:"4" | ERFORDERLICH: Der Apstra-VM werden 4 vCPU Cores zugeordnet, was der minimalen Herstellerempfehlung entspricht. |
env:CLAB_MGMT_PASSTHROUGH:"true" | ERFORDERLICH: Sorgt dafür, dass das MGMT-Interface der VM direkt in das MGMT-Netz gebridget wird, sodass die VM selbst direkt mit der MGMT-IP adressiert werden kann. |
startup-delay:180 | OPTIONAL: Die Apstra VM wird erst nach 3 min gestartet, sodass die cEOS-Nodes im Vorfeld ausreichend Zeit zum booten haben. |
ports: 80:80 443:443 | ERFORDERLICH: Exponiert die Ports des Web-Servers auf Ebene des WSL-Hosts, sodass ich von Windows aus direkt auf die Apstra Web-UI zugreifen kann. |
Hier die resultierende Topologie-Definition im Containerlab YAML-Format:
name: apstra-ceos
mgmt:
network: apstra-mgmt
ipv4-subnet: 172.20.20.0/24
ipv4-gw: 172.20.20.1
topology:
groups:
cEOS:
kind: arista_ceos
image: ceos:4.33.7M
startup-config: ceos-custom.conf
alpine:
kind: linux
image: alpine:latest
nodes:
apstra:
kind: generic_vm
image: vrnetlab/juniper_apstra:6.1.1-70
mgmt-ipv4: 172.20.20.10
env:
QEMU_MEMORY: "16384"
QEMU_SMP: "4"
CLAB_MGMT_PASSTHROUGH: "true"
startup-delay: 180
ports:
- 80:80
- 443:443
spine1:
group: cEOS
mgmt-ipv4: 172.20.20.11
spine2:
group: cEOS
mgmt-ipv4: 172.20.20.12
leaf1:
group: cEOS
mgmt-ipv4: 172.20.20.13
leaf2:
group: cEOS
mgmt-ipv4: 172.20.20.14
host1:
group: alpine
mgmt-ipv4: 172.20.20.21
exec:
- ip addr add 10.1.100.10/24 dev eth1
- ip route add 10.1.0.0/16 via 10.1.100.1
host2:
group: alpine
mgmt-ipv4: 172.20.20.22
exec:
- ip addr add 10.1.200.10/24 dev eth1
- ip route add 10.1.0.0/16 via 10.1.200.1
links:
- endpoints: [ "spine1:eth1", "leaf1:eth1" ]
- endpoints: [ "spine1:eth2", "leaf2:eth1" ]
- endpoints: [ "spine2:eth1", "leaf1:eth2" ]
- endpoints: [ "spine2:eth2", "leaf2:eth2" ]
- endpoints: [ "host1:eth1", "leaf1:eth3" ]
- endpoints: [ "host2:eth1", "leaf2:eth3" ]
links definiert werden.Initialer Deploy
Nun kann das Lab mithilfe des deploy Commands gestartet werden:
[*]─[LAPTOP]─[~/labs]
└──> clab deploy -t apstra-ceos.clab.yml
Containerlab wird zuerst die cEOS-Nodes und Linux-Testhosts starten, sowie die Links untereinander aktivieren. Nachdem die 180s startup-delay der Apstra-VM abgelaufen sind, wird auch diese gestartet.
Bei meinem Setup dauert es ca. 2-3 Minuten, bis Apstra gebootet hat und als healthy markiert wird. Ihr könnt den Vorgang mithilfe von docker logs -f <apstra-container-id> überprüfen und nachvollziehen. Am Ende sollte es in etwa so aussehen:
DEBUG Starting vrnetlab Apstra
DEBUG VMs: [<__main__.Apstra_vm object at 0x76446b9cbfb0>]
DEBUG VM not started; starting!
[...]
INFO Launching Apstra_vm arch x86_64 with 4 SMP/VCPU and 16384 M of RAM
INFO Scrapli: Disabled
INFO Transparent mgmt interface: Enabled
DEBUG number of provisioned data plane interfaces is 0
DEBUG qemu cmd: qemu-system-x86_64 -enable-kvm -display none -machine pc -chardev socket,id=monitor0,host=::,port=4000,server=on,wait=off -monitor chardev:monitor0 -chardev socket,id=serial0,host=::,port=5000,server=on,wait=off,telnet=on -serial chardev:serial0 -m 16384 -cpu host -smp 4 -drive if=ide,file=/config/apstra_overlay.qcow2 -device virtio-net-pci,netdev=p00,mac=0C:00:ca:bb:42:00 -netdev tap,id=p00,ifname=tap0,script=/etc/tc-tap-mgmt-ifup,downscript=no
DEBUG Apstra login prompt detected
INFO Startup complete in: 0:02:07.325491
docker exec -it <apstra-container-id> telnet 127.0.0.1 5000
Beim ersten Login mit den Standard-Credentials admin:admin läuft der initiale Konfigurationsdialog von Apstra durch, in dem man das CLI-Passwort setzt, das MGMT-Interface konfiguriert und schließlich auch das Passwort für die Web-UI festglegt:
┌─────────┤ Apstra Server first boot configuration tool (aos-config) ├─────────┐
│ │
│ 1 Local credentials Manage password for the default user (admin) │
│ 2 WebUI credentials Manage password for the default Apstra UI user (adm │
│ 3 Network Manage network configuration (e.g.: IP address, def │
│ 4 IP addressing mode Set AOS internal IP addressing mode (IPv4 or IPv6) │
│ 5 Apstra service Enable or Disable Apstra service │
│ 6 Set SSRN Set Software Support Reference Number │
│ │
│ <Ok> <Cancel> │
│ │
└──────────────────────────────────────────────────────────────────────────────┘
172.20.20.10.Nachdem sämtlich Einstellungen getroffen wurden, kann der erste Login auf die Web-UI erfolgen. Dafür öffnen wir einfach auf unserem Windows-Host einen beliebgen Browser und geben in die Adresszeile https://localhost ein. Da wir die HTTP-/HTTPS-Ports der Apstra-VM im CLAB-File auf der WSL-Ebene exponiert haben, können wir so direkt auf das Apstra-Frontend zugreifen. Der Login erfolgt mit dem User admin und dem zuvor definierten Web-UI Passwort.
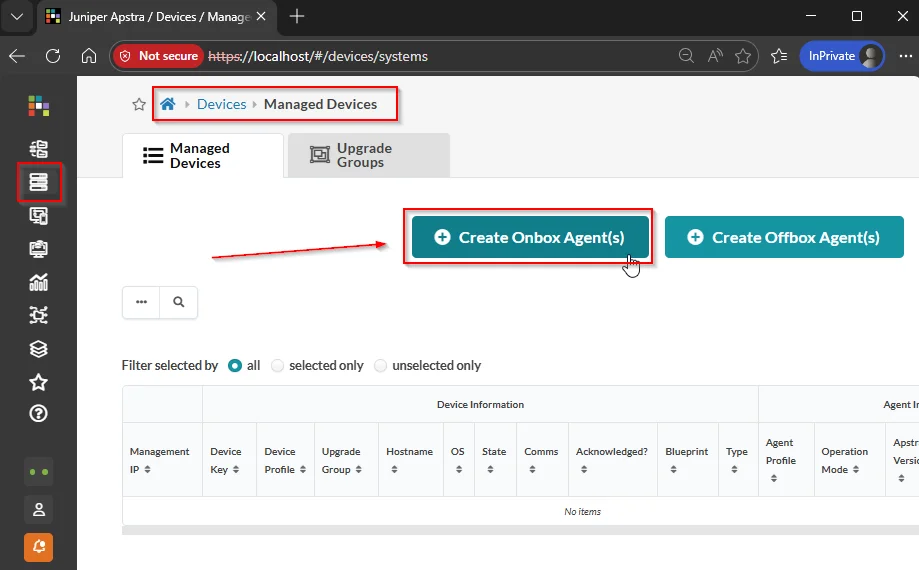
Device Onboarding
Im Anschluss können wir die einzelnen Arista cEOS-Nodes onboarden, die unsere DC-Fabric bilden sollen. Dazu navigieren wir in Apstra zum Menüpunkt “Devices” > “Managed Devices” und klicken auf “Create Onbox Agent(s)”
172.20.20.11 - 172.20.20.14, sowie die Standard Admin-Credentials admin:admin für dem System-Zugriff per SSH.
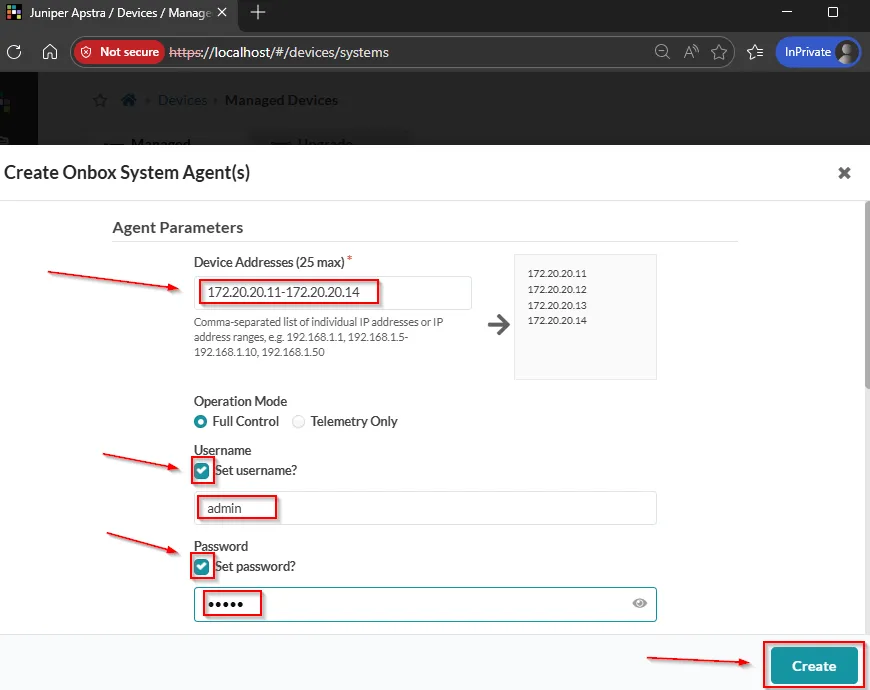
startup-config: ceos-custom.conf übergeben, enthält eine leicht angepasste Variante der Standard-Config, die aber sämtliche Anforderungen für das Apstra-Onboarding erfüllt.Wenn die Agent-Jobs erfolreich durchgelaufen sind, muss noch eine kleine manuelle Anpassung für jedes Device über die Managed Devices Übersichtsseite durchgeführt werden. Da Apstra das Device-Profile der cEOS-Nodes scheinbar nicht automatisch erkennt, müssen hier per Klick auf die MGMT-IP und Edit System die folgenden Parameter händisch ausgewählt/eingetragen werden:
- Device Profile: Arista vEOS
- Admin State: Normal
- Upgrade Group: default
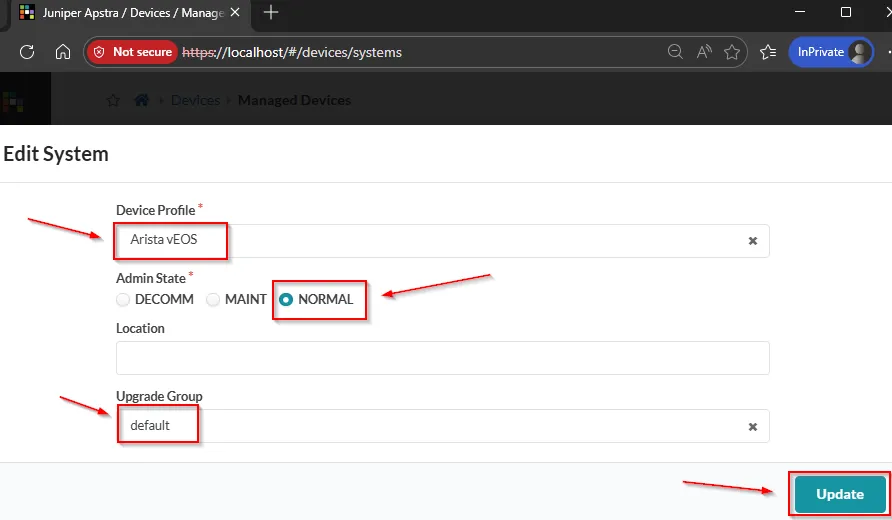
 Wichtig sind hier vor allem der korrekte Device Profile Typ Arista vEOS, sowie die grün markierten Comms/Acknowledged Werte.
Wichtig sind hier vor allem der korrekte Device Profile Typ Arista vEOS, sowie die grün markierten Comms/Acknowledged Werte.Fabric-Deployment
Da die cEOS-Nodes nun vollständig integriert sind, kann als nächstes der gewünschte Blueprint in Apstra angelegt und modelliert werden. Ich wähle für mein Beispiel-Setup eine 3-stage Clos EVPN/VXLAN Fabric gem. der Apstra Standard DC-Referenzarchitektur.
Im Anschluss daran kann der Status im Active-Tab verfolgt werden. Sofern alle Probes grün sind und keine Anomalien auftreten, dann ist der Intent erfoglreich deployed wurden. Die Gesamt-Übersicht sollte dann wie folgt aussehen:

Am Beispiel des Leaf-1 Nodes lässt sich gut erkennen, dass sowohl die Spine-Uplinks aktiv und gem. Intent konfiguriert sind, als auch der Port zum Host-1:

E2E Konnektivität
In meinem Beispiel-Setup sind die beiden Test-Hosts in verschiedenen Subnets des gleichen Tenants/VRFs angebunden. Die Host-seitigen IP- und Routingeinstellungen habe ich bereits im Containerlab-Topologiefile per exec Parameter definiert, sodass die zugehörigen Commands direkt beim Starten der Container ausgeführt werden
- Host1: 10.1.100.10/24 - Gateway: 10.1.100.1
- Host2: 10.1.200.10/24 - Gateway: 10.1.200.1
Mit diesem Setup möchte ich demonstrieren, dass das notwendige Inter-Subnet Routing über die cEOS-Fabric unter Verwendung von Anycast-Gateways erfolgen muss. Die dafür notwendigen Bausteine, wie Routing-Zone, Virtual Networks und Conenctivity Templates habe ich im Blueprint bereits entsprechend definiert, sodass der finale E2E-Erreichbarkeitstest zwischen den Hosts erfolgen kann:
/# ip addr | grep eth1
28: eth1@if29: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 9500 qdisc noqueue state UP
inet 10.1.100.10/24 scope global eth1
/# ping 10.1.200.10
PING 10.1.200.10 (10.1.200.10): 56 data bytes
64 bytes from 10.1.200.10: seq=0 ttl=62 time=4.972 ms
64 bytes from 10.1.200.10: seq=1 ttl=62 time=2.946 ms
64 bytes from 10.1.200.10: seq=2 ttl=62 time=3.982 ms
^C
--- 10.1.200.10 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 2.946/3.966/4.972 ms
docker exec -it <host1-container-id> sh bzw. über die Containerlab VS Code Extension -> “Attach Shell”Auch ein Blick in die EVPN Tabelle vom cEOS-Leaf1 zeigt, dass entsprechende EVPN-Routen vom Typ-2, -3 und -5 erfolgreich zwischen den Nodes ausgetauscht werden:
leaf1#sh bgp evpn
BGP routing table information for VRF default
Router identifier 203.0.113.2, local AS number 64514
Route status codes: * - valid, > - active, S - Stale, E - ECMP head, e - ECMP
c - Contributing to ECMP, % - Pending best path selection
Origin codes: i - IGP, e - EGP, ? - incomplete
AS Path Attributes: Or-ID - Originator ID, C-LST - Cluster List, LL Nexthop - Link Local Nexthop
Network Next Hop Metric LocPref Weight Path
* > RD: 203.0.113.2:100 mac-ip 001c.7300.0001
192.168.0.0 - - 0 i
RD: 203.0.113.3:200 mac-ip 001c.7300.0001
192.168.0.0 - 100 0 64513 64515 i
RD: 203.0.113.3:200 mac-ip 001c.7300.0001
192.168.0.0 - 100 0 64512 64515 i
* >Ec RD: 203.0.113.3:200 mac-ip aac1.ab98.af7a
192.168.0.1 - 100 0 64513 64515 i
* ec RD: 203.0.113.3:200 mac-ip aac1.ab98.af7a
192.168.0.1 - 100 0 64512 64515 i
* >Ec RD: 203.0.113.3:200 mac-ip aac1.ab98.af7a 10.1.200.10
192.168.0.1 - 100 0 64513 64515 i
* ec RD: 203.0.113.3:200 mac-ip aac1.ab98.af7a 10.1.200.10
192.168.0.1 - 100 0 64512 64515 i
* > RD: 203.0.113.2:100 imet 192.168.0.0
- - - 0 i
* >Ec RD: 203.0.113.3:200 imet 192.168.0.0
192.168.0.1 - 100 0 64513 64515 i
* ec RD: 203.0.113.3:200 imet 192.168.0.0
192.168.0.1 - 100 0 64512 64515 i
* >Ec RD: 203.0.113.3:200 imet 192.168.0.1
192.168.0.1 - 100 0 64513 64515 i
* ec RD: 203.0.113.3:200 imet 192.168.0.1
192.168.0.1 - 100 0 64512 64515 i
* > RD: 203.0.113.2:100 imet 192.168.0.2
- - - 0 i
* > RD: 203.0.113.2:10 ip-prefix 10.1.100.0/24
Lab-Zustand erhalten
Wer sich jetzt fragt, ob man seinen Laptop für immer laufen lassen muss, um den Zustand des Labs und der Apstra-VM zu erhalten, den kann ich beruhigen.
Das Apstra-Image, welches wir durch den Custom Build-Ordner für vrnetlab erstellt haben, beinhaltet die Verwendung eines Persistent-Overlay Images. Das bedeutet, dass für jede Apstra-Node automatisch ein individuelles QCOW2-Overlay Image erstellt und persistent auf dem Containerlab-Host gesichert wird. Das Image ist jeweils unter folgendem Pfad zu finden:
<lab-name>/
└── <apstra-node-name>/
└── config/
└── apstra_overlay.qcow2 ← Persistent Overlay Image
Dadurch wird ermöglicht, dass Labs nach der Nutzung einfach per clab destroy gestoppt und zu einem späteren Zeitpunkt per clab deploy wieder mit dem gleichen Zustand gestartet werden können.
Fazit
In diesem eher langen und umfangreichen Blog-Post habe ich im Prinzip einen mehrwöchigen Prozess dokumentiert - von der ersten Idee eine kleine Apstra-managed DC-Fabric in Containerlab auf einem Windows-Laptop zu nutzen, bis hin zur finalen Umsetzung und dem erfolgreichen Test.
Auch wenn hier zu guter Letzt nur das fertige und funktionierende Endergebnis präsentiert wird, war der Weg durchaus von diversen Rückschlägen, Neuausrichtungen und Zweifeln geprägt. Letztlich sind aber genau diese Erfahrungen wichtig, um sich weiterzuentwickeln, neue Skills aufzubauen und an den Herausforderungen zu wachsen - und zugegebenermaßen hat das Ganze durchaus auch Spaß gemacht. 😊
Mit dem Ergebnis bin ich durchaus zufrieden und ich finde es ziemlich beeindruckend, dass es damit möglich ist, eine vollumfänglich durch Apstra-verwaltete EVPN/VXLAN-Fabric bestehend aus vier cEOS-Nodes auf einem Windows-Laptop mit 32GB RAM laufen zu lassen. 😎
Darüber hinaus eröffnet die Möglichkeit Apstra direkt als Teil der Containerlab-Topologie zu verwenden, zusätzlich weitere denkbare Anwendungsfälle. Insbesondere wenn die zu verwaltenden DC-Topologien größer werden, mehrere Pods inkl. DCI umfassen bzw. wenn auch ressourcenhungrige VM-basierte Nodes (wie z.B. vJunosSwitch) dabei verwendet werden sollten, kommt man mit einem Laptop sehr schnell an seine Grenzen. Aber da das komplette Lab inkl. Apstra gewissermaßen portabel ist, kann man es bspw. auch einfach ohne weiteres auf Github Codespaces oder in Clabernetes hosten und so die Grenzen des eigenen Laptops überwinden. 💡
Wer das Ganze selbst ausprobieren möchte, der kann aktuell meinen persönlichen vrnetlab-Branch mit dem Custom Apstra Build-Ordner nutzen, solange der zugehörige PR im SRL-Labs vrnetlab Repo noch nicht gemerged ist. Die zugehörigen Lab-Files sind wie immer ebenfalls in den Data Autobahn Labs auf Github zu finden.